
A Story You’ll Never Forget
Building a Machine Learning model is not about typing .fit() and expecting magic. In the real world, it feels more like running a restaurant than writing code.
Imagine you are opening a premium pizza shop called “Predicta Pizza” in 2026. Your goal is simple but ambitious. You want to use AI to predict exactly how many pizzas to prepare each day so you never waste ingredients and never disappoint customers.
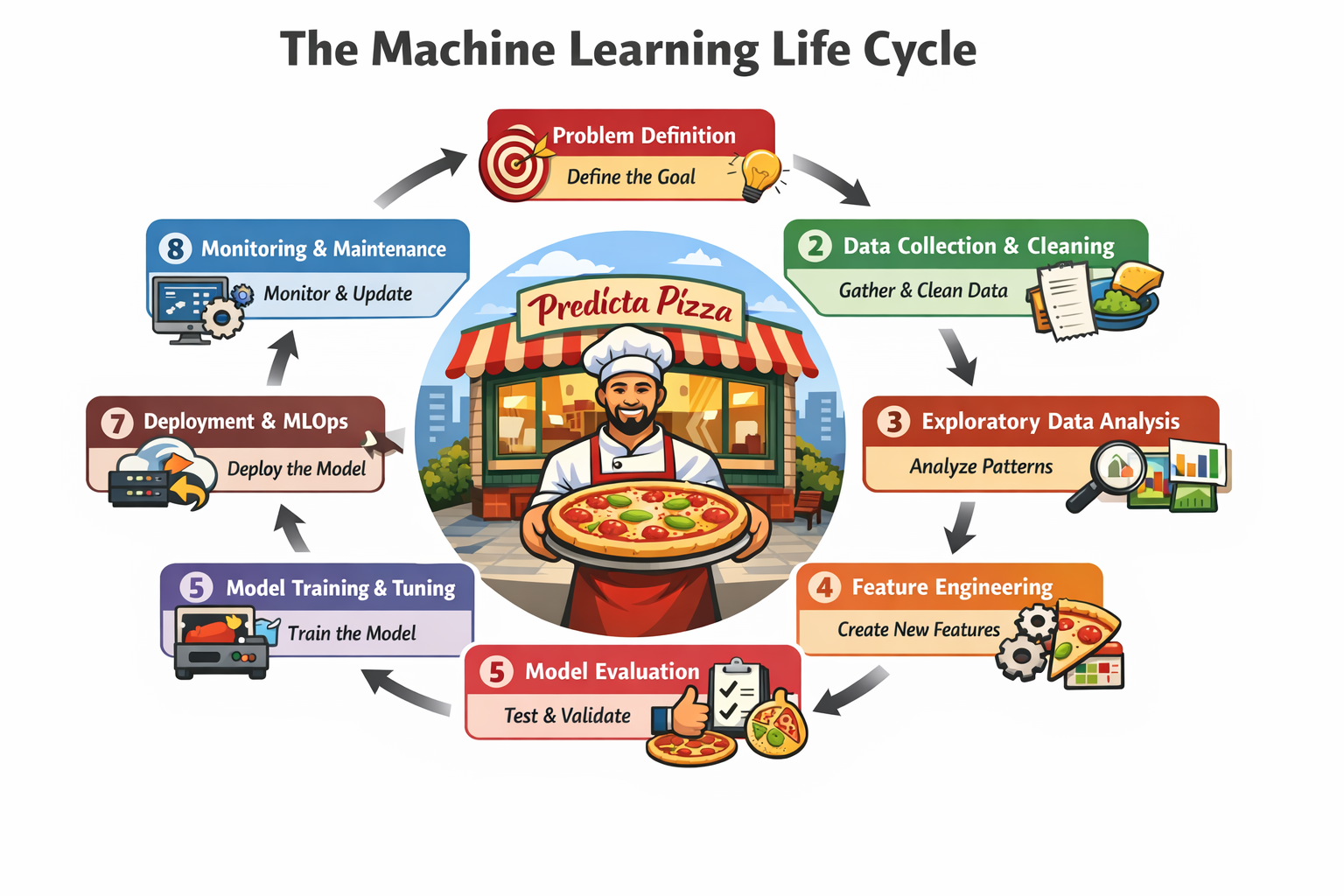 ML Lifecycle
ML LifecycleHere is how the Machine Learning Life Cycle unfolds.
The Dream: Problem Definition
Before buying ovens or hiring chefs, you define your goal clearly.
You say, “I want to predict daily pizza demand within 5 percent accuracy so I can reduce waste and maximize profit.”
If you skip this step, your AI might give you something useless, like average sales across the year. That does not help when Friday nights are ten times busier than Mondays.
In Machine Learning, this stage defines the business objective, the success metric, and whether ML is even required. Sometimes a simple rule works better than a complex model. Clarity at the beginning saves enormous time later.
The Ingredient Hunt: Data Collection and Cleaning
Now you gather data. You look at old receipts, weather reports, holiday calendars, and local stadium events.
But the data is messy. Some receipts are missing dates. Some totals are incorrect. Some entries are duplicated.
This is reality.
Most Machine Learning projects spend the majority of their time here. You remove duplicates, handle missing values, correct inconsistencies, and structure everything neatly.
You cannot bake a premium pizza with spoiled ingredients. Clean data is the foundation of everything that follows.
The Detective Phase: Exploratory Data Analysis
Before cooking, you study patterns.
You notice that sales double during cricket matches. Rainy days increase delivery orders. Mondays are consistently slow.
This is Exploratory Data Analysis. You use statistics and visualizations to understand what the data is trying to tell you.
You are not building yet. You are learning.
EDA helps uncover correlations, detect bias, understand distributions, and identify anomalies. It is like tasting each ingredient before deciding on the recipe.
The Secret Sauce: Feature Engineering
Raw data alone is not powerful.
Instead of using just the date, you create meaningful signals such as whether it is a weekend, a holiday, a rainy day, or close to salary credit dates.
This is where the art of data science appears. You transform ordinary inputs into features that reflect real human behavior.
Often, well engineered features improve performance more than switching algorithms.
You may also scale numerical values or remove noisy variables. Each improvement sharpens the recipe.
The Oven Test: Model Training and Tuning
Now you test different ovens.
You might try Linear Regression for simplicity, Random Forest for stability, XGBoost for performance, or Neural Networks for flexibility.
You divide your data into training, validation, and test sets. The model learns from the training data. You tune settings using validation data. Finally, you reserve unseen test data for honest evaluation.
You adjust hyperparameters carefully. Too much complexity leads to overfitting where the model memorizes past patterns. Too little complexity leads to underfitting where it learns almost nothing useful.
Balance is critical.
The Food Critic: Evaluation
Before opening your shop, you ask someone who has never tasted your pizza to give honest feedback. That is your test set.
This step confirms whether the model generalizes well. It ensures your predictions work in the real world and not just on historical data.
Evaluating on training data would be like giving students the answer key before the exam. It creates a false sense of success.
Grand Opening: Deployment and MLOps
Now the model goes live.
Every morning at 8 AM, it checks the weather forecast and event calendar and predicts how many pizzas to prepare. The chef receives a number and plans inventory accordingly.
Behind the scenes, the model runs in cloud infrastructure, serves predictions through APIs, and is maintained through continuous integration and deployment practices.
A model sitting on your laptop is a project. A deployed model serving real users is a product.
The Reality Check: Monitoring and Maintenance
A month later, a new burger shop opens nearby. Sales drop suddenly.
Your model still predicts the old numbers. Performance declines. This is model drift.
The environment changed. Customer behavior shifted.
You monitor performance regularly, collect new data, retrain the model, and restart the cycle when needed.
Machine Learning is not a straight line. It is a continuous loop.
The Bigger Lesson
Machine Learning success does not depend only on algorithms. It depends on clear problem framing, clean data, thoughtful feature engineering, disciplined evaluation, and constant monitoring.
The algorithm is only one part of a larger system.
Treat Machine Learning like a one time coding exercise and it will fail. Treat it like running a living business that requires continuous improvement and it will scale.
That is the true Machine Learning Life Cycle.
Writer : Garima Srivastava | Product Mindset